Teaching an AI to play volleyball in 5 minutes
With the pandemic still not allowing us to enjoy sports in a group, I wanted to use a hackathon at
TwentyBN to at least play some volleyball with an AI ![]()
![]()
The open-source toolkit Sense together with TwentyBN’s pretrained models provides an easy way to create your own video recognition models. My plan was to use this transfer learning toolkit to teach the machine two new tasks:
- Recognizing different volleyball techniques
- Counting contacts for those techniques
All of that should be done within the scope of one hackathon day, including data collection, training and visualization of the results.
TL;DR: Only five minutes of training video material were enough to create a confident classifier and a counting model that worked alright. Of course there is still a lot that could be improved, but I was really happy about this quick proof of concept. See the videos at the end of this post for an impression.
Data Collection
For the data collection (in December ![]() ), I chose four common volleyball techniques as well as five other
actions to serve as background data.
), I chose four common volleyball techniques as well as five other
actions to serve as background data.
Techniques




Background





Overall, 38 videos of varying length were collected and split into test and validation data:
| Training | Validation | |
|---|---|---|
| Forearm Passing | 4 Videos, 69s | 2 Videos, 14s |
| Overhead Passing | 4 Videos, 72s | 2 Videos, 20s |
| One Arm Passing | 5 Videos, 38s | 2 Videos, 7s |
| Pokey | 6 Videos, 28s | 2 Videos, 6s |
| Nothing | 1 Video, 12s | 1 Video, 5s |
| Holding | 1 Video, 7s | 1 Video, 6s |
| Bouncing | 2 Videos, 14s | 1 Video, 4s |
| Dropping | 1 Video, 18s | 1 Video, 12s |
| Leaving | 1 Video, 12s | 1 Video, 3s |
| Total | 25 Videos, 270s | 13 Videos, 77s |
In order to be able to count events in the videos, we also need to annotate those on a frame-level.
SenseStudio provides an easy interface for that, but it still takes some time going through all videos and assigning
tags everywhere.
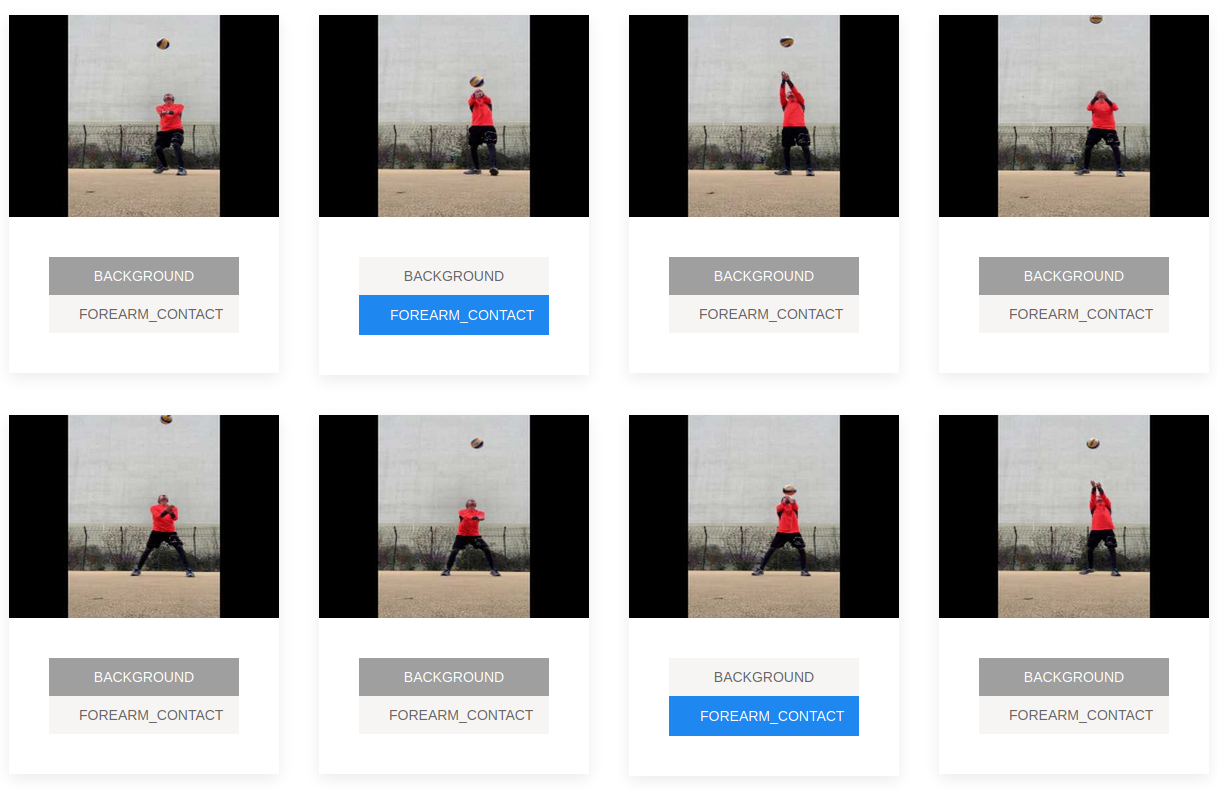
Classification
Now it’s time to train the first model! With StridedInflatedEfficientNet-pro as the pretrained backbone model, it is
usually helpful to not only add our new classification head, but also fine-tune the last 9 backbone layers. This
includes two of the temporal 3D convolution layers, which gives your updated model more capability to learn new motions.
The confusion matrix on the validation set looks like this:
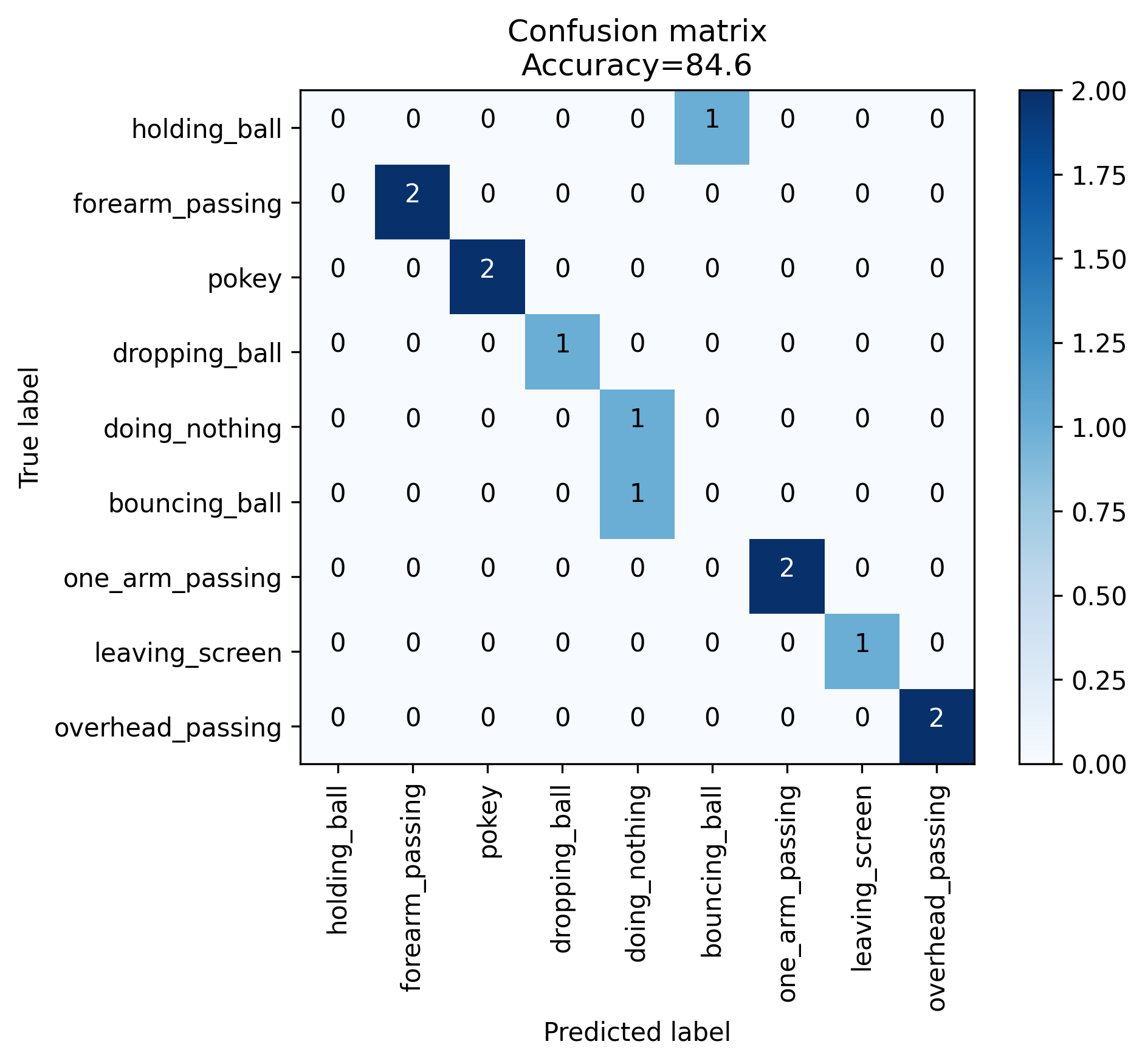
As you can see, the model still has difficulties distinguishing the background classes where it had even less data, but on the four main techniques it makes no mistakes. Now let’s see it in action on a video clip of different techniques in sequence:
Again, the background classes in the beginning are not really confidently predicted. In the rest of the video however the used techniques are always recognized with only a short delay, even in some cases where different actions happen in quick succession. This is especially impressive as the model was only trained on longer clips of single techniques that were repeated over and over again.
Counting
When training the model on temporal annotations instead, it doesn’t make as much sense to examine the confusion matrix, as the events to be detected are only labeled for one frame, so if the model is just one step late in its prediction, that would be counted as a miss. Furthermore, a few tricks can be applied in post-processing to make the counting a little more stable, e.g. only counting rising flanks of model outputs or using two markers to count an action with multiple key points. Therefore, let’s directly take a look at the model’s behavior in practice:
Here is a comparison with what the model should have predicted:
| Target | Prediction | |
|---|---|---|
| Forearm Passing | 10 | 10 |
| Overhead Passing | 20 | 17 |
| Pokey | 3 | 3 |
| One Arm Passing | 3 | 3 |
| Bouncing | 3 | 2 |
Clearly, the model missed a few contacts and - to be fair - not all the counted ones were counted at the right time. Still, for a model that was trained in a short time on very little data, this is already a promising outcome.
Next Steps
These results have been obtained on data from just one person and thresholds have been tuned for these demo videos, so I expect bad generalization performance. An obvious next step would be to record more data in different settings and starring more people.
It could also be very helpful to record and annotate sequences of varying actions, just as shown in the demo videos. Those should enable the model to react even more quickly to changes and count each single move.
For now, these first results make me really optimistic, and I am looking forward to seeing what other exciting
applications of the Sense video recognition toolkit are possible!